Keep your ARMS and LEGS: Assuaging VRAM and Training Speed constraints in Language Embedded 3D Gaussian Splats
Project Overview
We present an optimization to the Foundation Model Embedded Gaussian Splatting (FMGS) pipeline for open-vocabulary 3D scene understanding. FMGS combines 3D Gaussian Splatting (3DGS) with foundation vision-language models like CLIP and DINO, but suffers from high VRAM usage and slow training due to its use of multi-resolution hash encodings (MHEs) passed into per-Gaussian MLP decoders.
To address this, we propose an alternative pipeline that renders the MHE directly into a feature field and then applies parameter-efficient CNNs to decode semantic features. This change leads to faster training, reduced memory usage, and more scalable inference, while preserving model accuracy.
Method
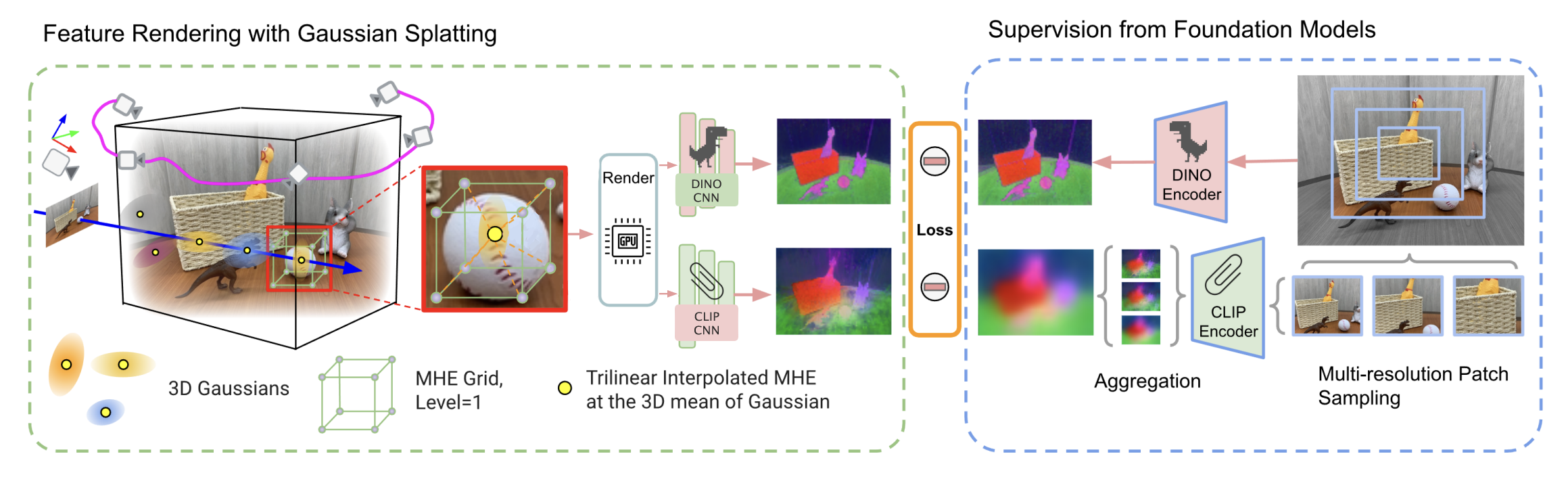
Figure 1. Our adjusted FMGS architecture
Our method follows the FMGS training pipeline, with the key change being the replacement of MLP-based per-Gaussian feature decoding with a rendered feature map + CNN approach:
- Render MHE feature field across the image plane
- Apply CLIP and DINO CNNs to the rendered feature maps
- Compare CNN outputs against frozen foundation model features from CLIP and DINO
- Use hybrid CLIP loss + DINO feature loss + pixel-alignment loss for supervision
This modification avoids storing per-Gaussian high-dimensional features and reduces GPU overhead, especially in large-scale scenes.
Results
1. Accuracy on Open-Vocabulary Object Detection
Our model achieves comparable or better accuracy than FMGS on multiple scenes from the LERF dataset when evaluated with open-vocabulary object queries. While the original FMGS achieves high accuracy, our model maintains similar performance despite architectural changes.
We evaluate open-vocabulary object detection accuracy on five scenes from the LERF dataset. A prediction is considered correct if the highest-scoring pixel from the relevancy map lies within the ground-truth bounding box.
| Scene | LERF | FMGS | Ours |
|---|---|---|---|
| bouquet | 83.3% | 91.7% | 100.0% |
| figurines | 87.2% | 79.5% | 79.5% |
| ramen | 62.5% | 80.0% | 82.5% |
| teatime | 96.9% | 87.5% | 90.6% |
| kitchen | 85.2% | DNF | 72.2% |
| Average | 83.0% | 84.7% | 84.96% |
2. Computational Efficiency
We reduce training time by 37% and VRAM usage by 24% on average compared to FMGS, enabling faster experimentation and broader accessibility on consumer GPUs.
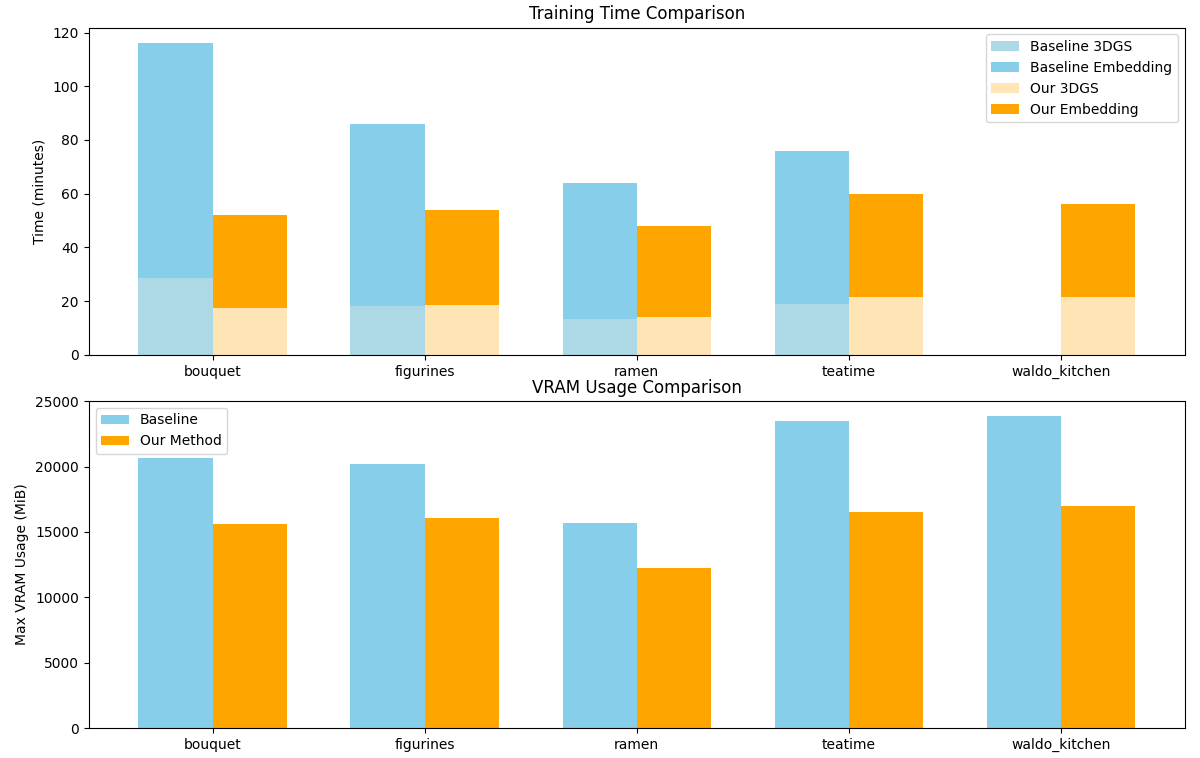
Figure 2. Runtime and memory usage comparison across five scenes. Our model is faster and more efficient than FMGS.
3. Qualitative Results
Our method produces relevancy maps that are spatially smoother and exhibit lower false activations in background regions, compared to FMGS. While FMGS often yields more intense responses, our approach better suppresses noise and maintains focus around queried objects.
Figure 3. Relevancy maps from FMGS (left) and our method (right) for the same query.